Q-space Conditioned Translation Networks for Directional Synthesis of Diffusion Weighted Images from Multi-modal Structural MRI
Mengwei Ren*, Heejong Kim*, Neel Dey, Guido Gerig
New York University
Abstract
Recent deep learning approaches for Diffusion MRI modeling circumvent the requirement of densely-sampled diffusion-weighted images (DWIs) by directly predicting microstructural indices from sparsely-sampled DWIs supervised with fully-sampled DWIs. However, they implicitly make unrealistic assumptions of static Q-space sampling during reconstruction. Further, such approaches restrict direct downstream estimations, such as tractography, from arbitrarily sampled DWIs unless we use model fitting methods spherical harmonics, for example.
We propose a generative adversarial translation framework for high-quality DW image estimation with arbitrary Q-space sampling given commonly acquired structural images. Our translation network linearly modulates its internal representations conditioned on continuous Q-space information, removing the need for fixed sampling schemes. Moreover, this approach enables the downstream estimation of high-quality microstructural maps from arbitrarily subsampled DWIs, which may be particularly important in cases with sparsely sampled DWIs. Across several recent methodologies, the proposed approach yields improved DWI synthesis accuracy and fidelity with enhanced downstream utility as quantified by the accuracy of scalar microstructure indices estimated from the synthesized images.
Framework overview
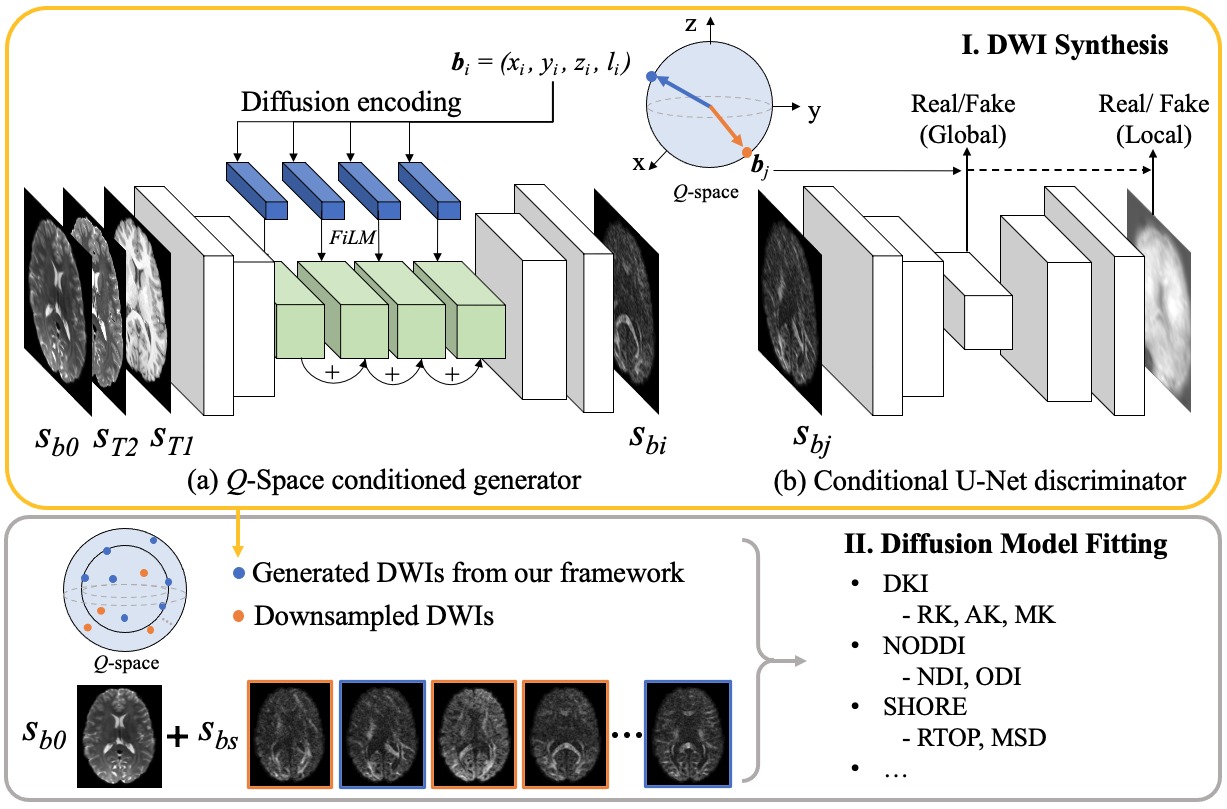
I. Our q-space conditioned translation framework. II. Once trained, the generator is able to synthesize DWIs along gradients in q-space (blue dots). Merged with arbitrarily downsampled DWIs, various microstructural indices can be calculated with diffusion model fitting.
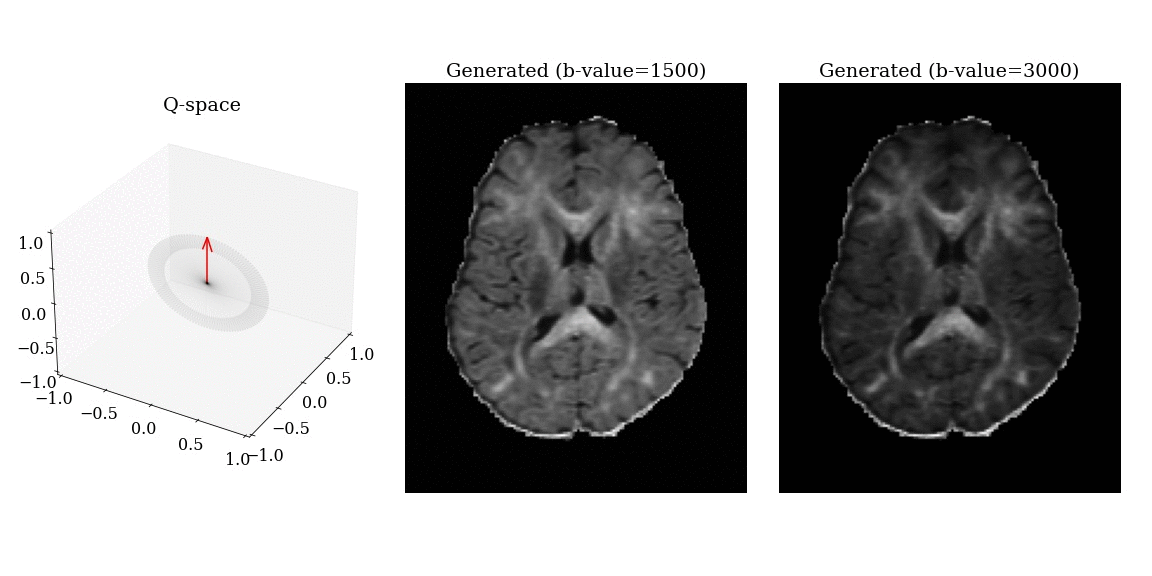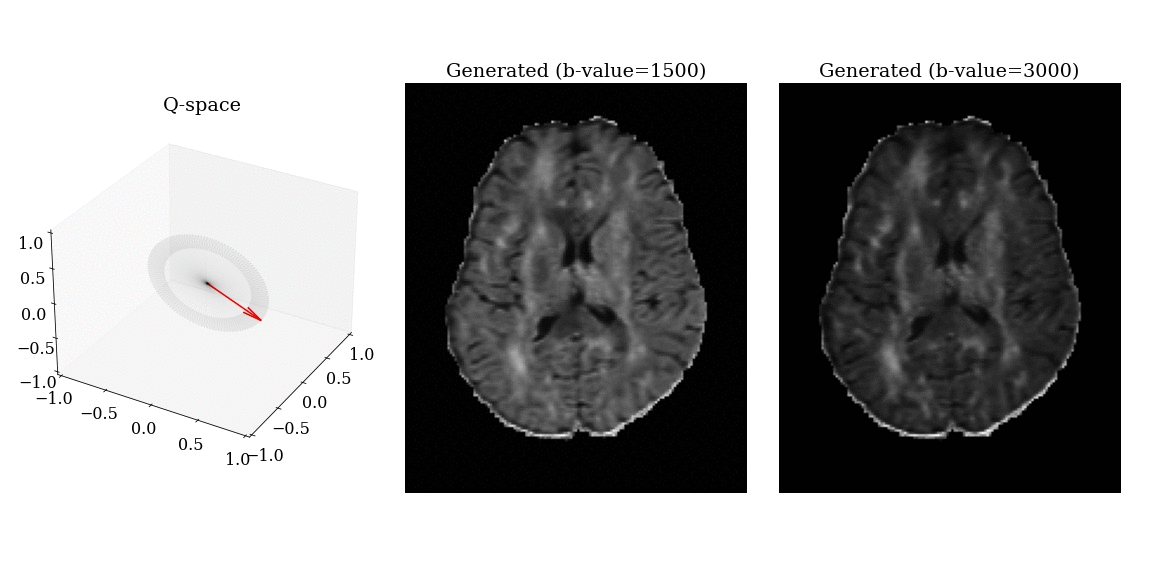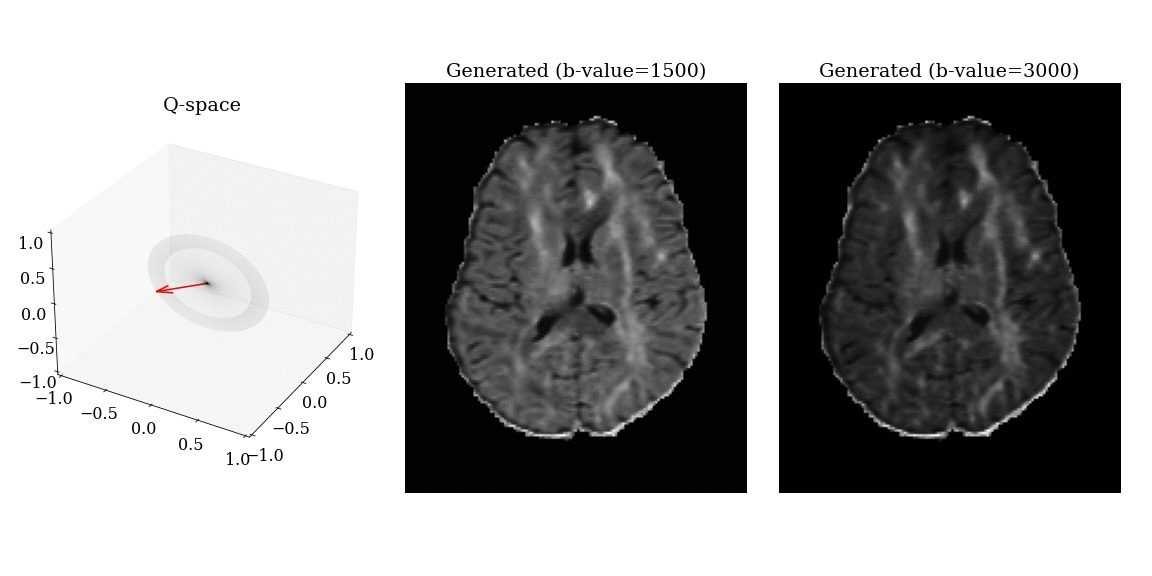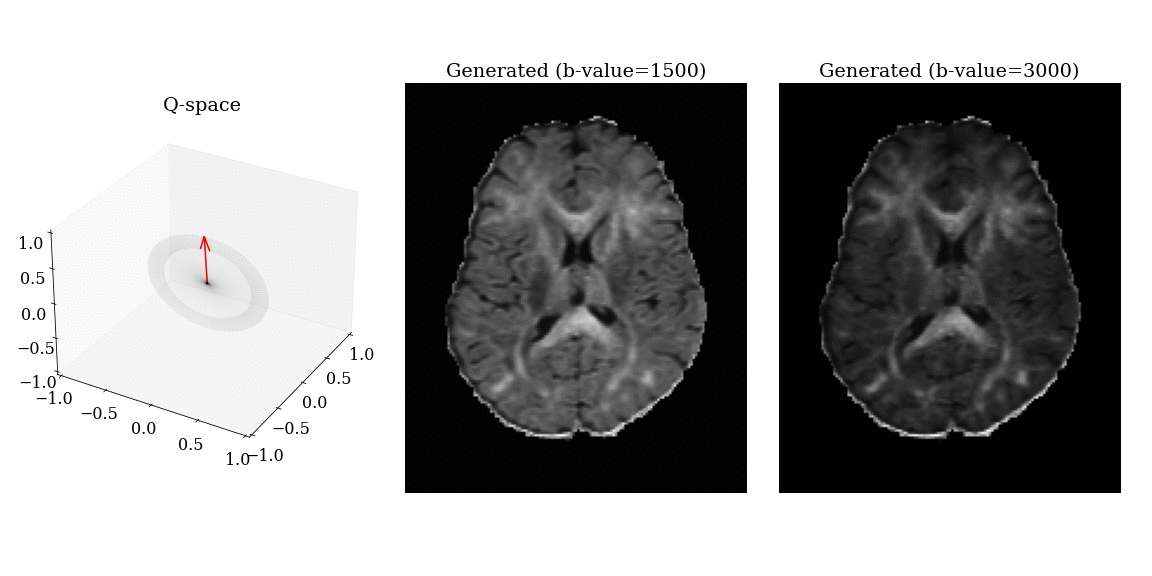
Synthesized DWI
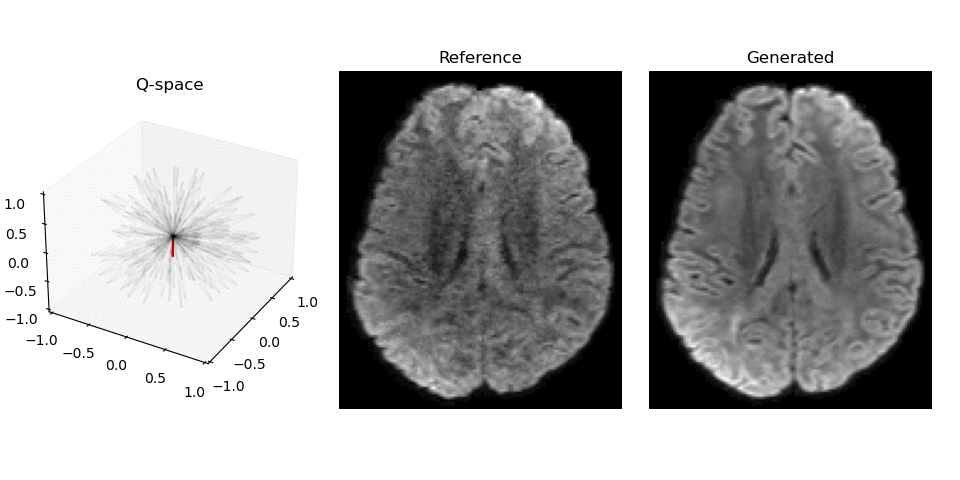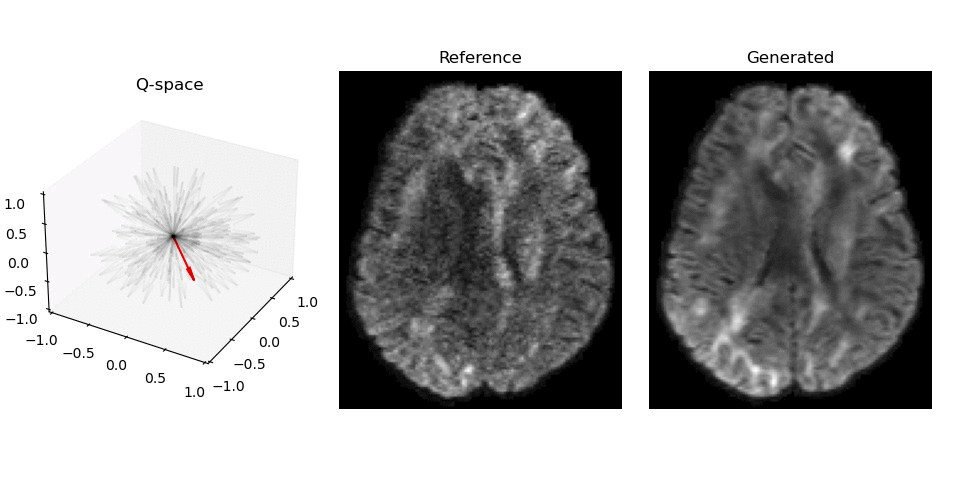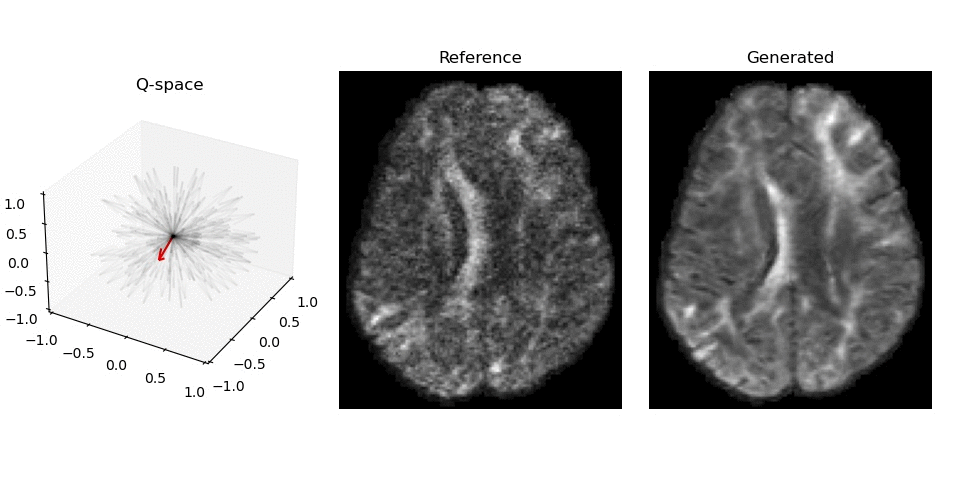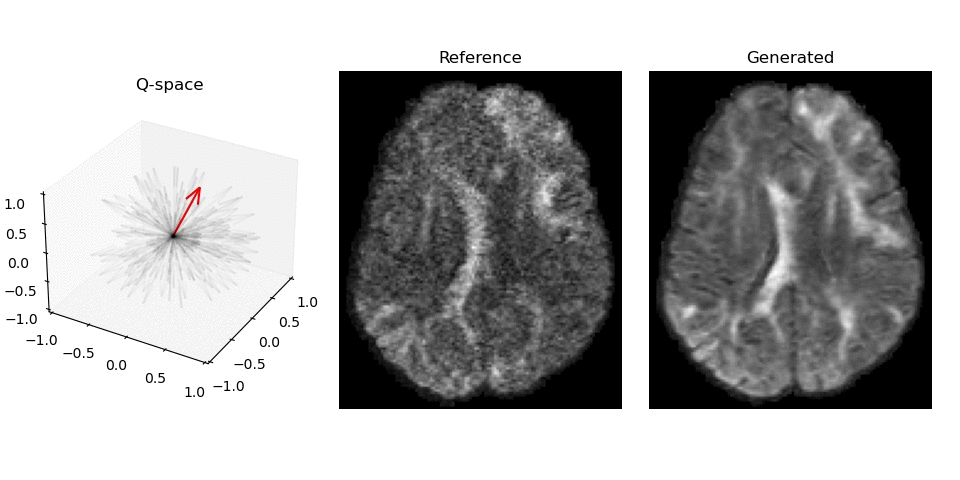
Synthesized DWI images (right) compared to reference image (middle) for different gradient vectors in q-space.
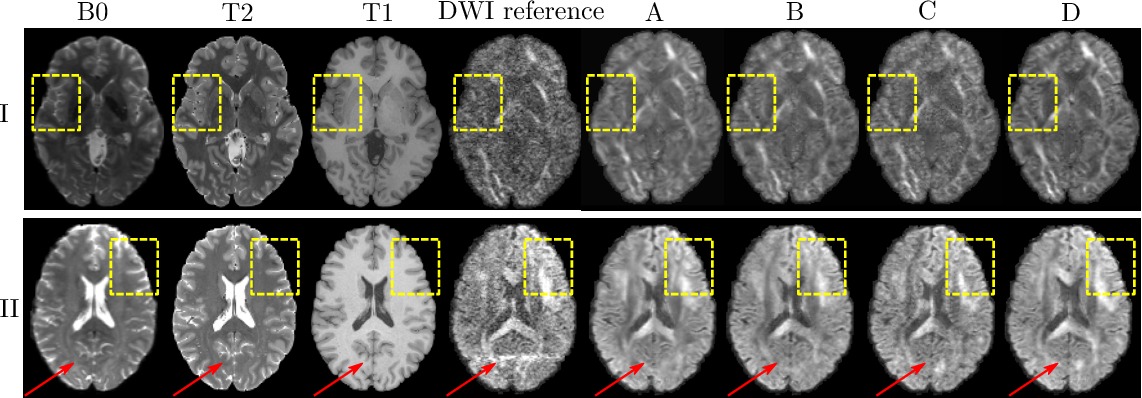
DWI synthesis results under various model configurations: A uses B0 as model input constrained by L1 loss only; B, C, D include additive adversarial components on top of A, while C and D take additional T2/T1 image as model input. All potential input channels (B0, T1, T2) are visualized on the left. I. shows translation results with a standard DWI slice in the test set as the reference; II. visualizes a test slice where artifacts (red arrows) appear in the reference DWI, which are corrected by the generated DWIs from our methods.
Microstructural estimation
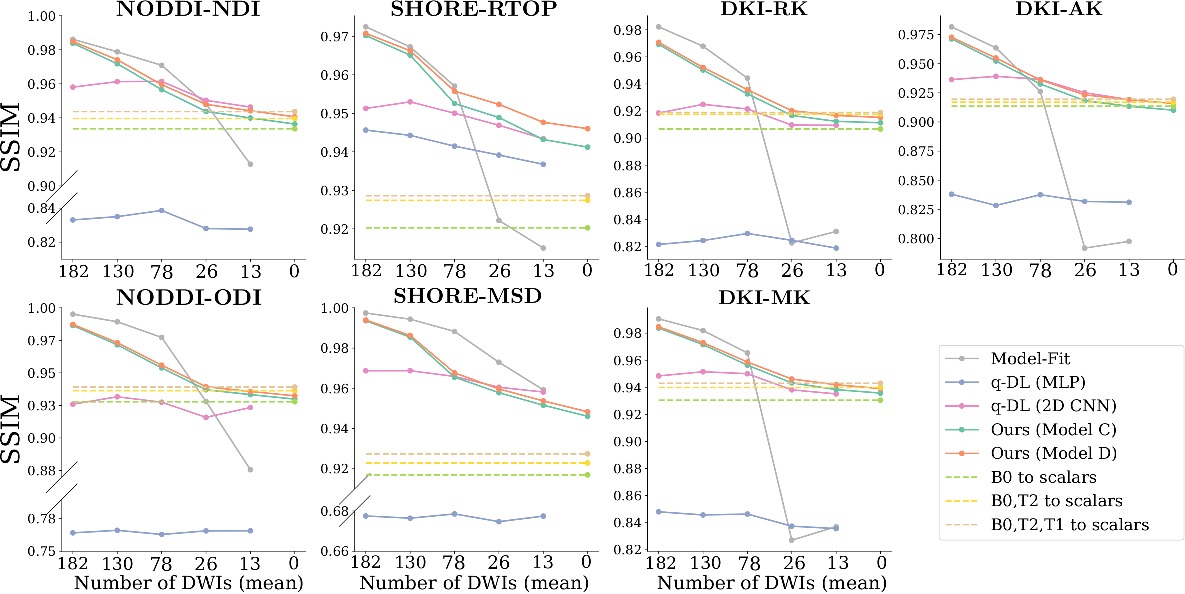
Quantitative microstructural estimation quality under varying DWI acquisition budgets as measured by SSIM (higher is better).
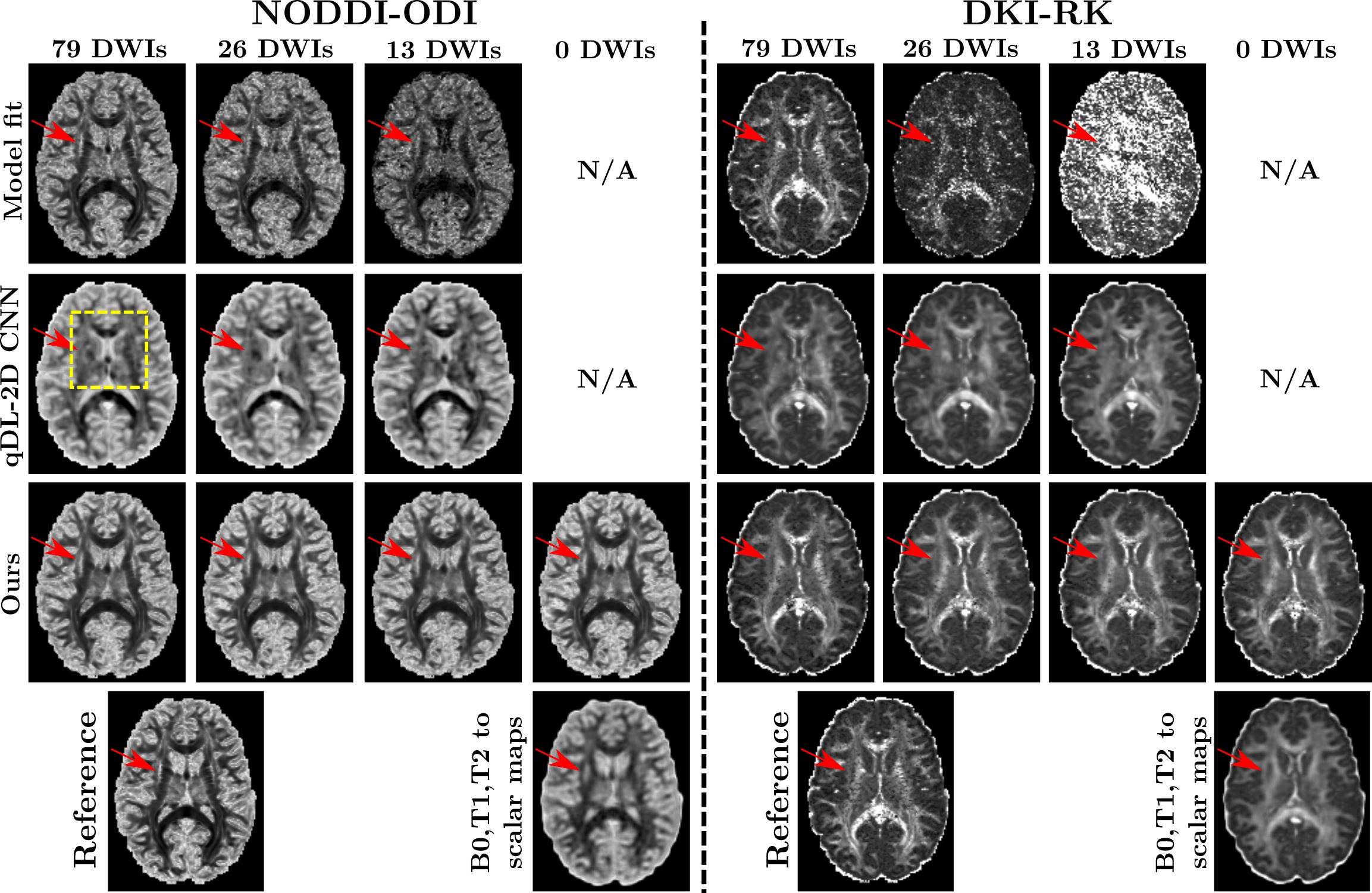
NODDI (ODI) and DKI (RK) scalar maps are estimated by different methods from arbitrarily downsampled DWIs. As the number of DWIs decreases, model-fitting results show strong quality degradation and qDL-2D produces inaccurate structural details (see yellow insets), whereas our method preserves microstructure with high fidelity (see external capsule/red arrows). Under fully synthetic settings (0 DWIs), our result displays improved fidelity compared to direct B0, T2, T1 to scalar translation.
Whole brain fiber-tractography from 26 sparsely-sampled DWIs (left), the results from fully-sampled DWIs (center), and results from our framework (right).
BibTeX
@misc { ren2021qspace,
title= { Q-space Conditioned Translation Networks for Directional Synthesis of Diffusion Weighted Images from Multi-modal Structural MRI } ,
author= { Mengwei Ren and Heejong Kim and Neel Dey and Guido Gerig } ,
year= { 2021 } ,
eprint= { 2106.13188 } ,
archivePrefix= { arXiv } ,
primaryClass= { eess.IV } {